


上篇文章給大家分享的是Spider類的使用,本次我們繼續(xù)分享學習Spider類的子類CrawlSpider類。
介紹CrawlSpider
CrawlSpider其實是Spider的一個子類,除了繼承到Spider的特性和功能外,還派生除了其自己獨有的更加強大的特性和功能。
比如如果你想爬取知乎或者是簡書全站的話,CrawlSpider這個強大的武器就可以爬上用場了,說CrawlSpider是為全站爬取而生也不為過。
其中最顯著的功能就是”LinkExtractors鏈接提取器“。Spider是所有爬蟲的基類,其設計原則只是為了爬取start_url列表中網(wǎng)頁,而從爬取到的網(wǎng)頁中提取出的url進行繼續(xù)的爬取工作使用CrawlSpider更合適。
CrawlSpider源碼分析
源碼解析
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
# 首先調用parse()來處理start_urls中返回的response對象
# parse()則將這些response對象傳遞給了_parse_response()函數(shù)處理,并設置回調函數(shù)為parse_start_url()
# 設置了跟進標志位True
# parse將返回item和跟進了的Request對象
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
# 處理start_url中返回的response,需要重寫
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
# 從response中抽取符合任一用戶定義'規(guī)則'的鏈接,并構造成Resquest對象返回
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
# 抽取之內的所有鏈接,只要通過任意一個'規(guī)則',即表示合法
for n, rule in enumerate(self._rules):
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
# 使用用戶指定的process_links處理每個連接
if links and rule.process_links:
links = rule.process_links(links)
# 將鏈接加入seen集合,為每個鏈接生成Request對象,并設置回調函數(shù)為_repsonse_downloaded()
for link in links:
seen.add(link)
# 構造Request對象,并將Rule規(guī)則中定義的回調函數(shù)作為這個Request對象的回調函數(shù)
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=n, link_text=link.text)
# 對每個Request調用process_request()函數(shù)。該函數(shù)默認為indentify,即不做任何處理,直接返回該Request.
yield rule.process_request(r)
# 處理通過rule提取出的連接,并返回item以及request
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
# 解析response對象,會用callback解析處理他,并返回request或Item對象
def _parse_response(self, response, callback, cb_kwargs, follow=True):
# 首先判斷是否設置了回調函數(shù)。(該回調函數(shù)可能是rule中的解析函數(shù),也可能是 parse_start_url函數(shù))
# 如果設置了回調函數(shù)(parse_start_url()),那么首先用parse_start_url()處理response對象,
# 然后再交給process_results處理。返回cb_res的一個列表
if callback:
#如果是parse調用的,則會解析成Request對象
#如果是rule callback,則會解析成Item
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
# 如果需要跟進,那么使用定義的Rule規(guī)則提取并返回這些Request對象
if follow and self._follow_links:
#返回每個Request對象
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, basestring):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
CrawlSpider爬蟲文件字段介紹
CrawlSpider除了繼承Spider類的屬性:name、allow_domains之外,還提供了一個新的屬性:rules。它是包含一個或多個Rule對象的集合。每個Rule對爬取網(wǎng)站的動作定義了特定規(guī)則。如果多個Rule匹配了相同的鏈接,則根據(jù)他們在本屬性中被定義的順序,第一個會被使用。
CrawlSpider也提供了一個可復寫的方法:
parse_start_url(response)
當start_url的請求返回時,該方法被調用。該方法分析最初的返回值并必須返回一個Item對象或一個Request對象或者一個可迭代的包含二者的對象。
注意:當編寫爬蟲規(guī)則時,請避免使用parse 作為回調函數(shù)。 由于CrawlSpider使用parse 方法來實現(xiàn)其邏輯,如果 您覆蓋了parse 方法,CrawlSpider將會運行失敗。
另外,CrawlSpider還派生了其自己獨有的更加強大的特性和功能,最顯著的功能就是”LinkExtractors鏈接提取器“。
LinkExtractor
class scrapy.linkextractors.LinkExtractor
LinkExtractor是從網(wǎng)頁(scrapy.http.Response)中抽取會被follow的鏈接的對象。目的很簡單: 提取鏈接?每個LinkExtractor有唯一的公共方法是 extract_links(),它接收一個 Response 對象,并返回一個 scrapy.link.Link 對象
即Link Extractors要實例化一次,并且 extract_links 方法會根據(jù)不同的 response 調用多次提取鏈接?源碼如下:
class scrapy.linkextractors.LinkExtractor(
allow = (), # 滿足括號中“正則表達式”的值會被提取,如果為空,則全部匹配。
deny = (), # 與這個正則表達式(或正則表達式列表)不匹配的URL一定不提取。
allow_domains = (), # 會被提取的鏈接的domains。
deny_domains = (), # 一定不會被提取鏈接的domains。
deny_extensions = None,
restrict_xpaths = (), # 使用xpath表達式,和allow共同作用過濾鏈接
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
作用:提取response中符合規(guī)則的鏈接。
參考鏈接:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/link-extractors.html
Rule類
LinkExtractor是用來提取的類,但是提取的規(guī)則需要通過Rule類實現(xiàn)。Rule類的定義如下:
class scrapy.contrib.spiders.Rule(link_extractor,callback=None,cb_kwargs=None,
follow=None,process_links=None,process_request=None)
參數(shù)如下:
link_extractor:是一個Link Extractor對象。其定義了如何從爬取到的頁面提取鏈接。
callback:是一個callable或string(該Spider中同名的函數(shù)將會被調用)。從link_extractor中每獲取到鏈接時將會調用該函數(shù)。該回調函數(shù)接收一個response作為其第一個參數(shù),并返回一個包含Item以及Request對象(或者這兩者的子類)的列表。
cb_kwargs:包含傳遞給回調函數(shù)的參數(shù)(keyword argument)的字典。
follow:是一個boolean值,指定了根據(jù)該規(guī)則從response提取的鏈接是否需要跟進。如果callback為None,follow默認設置True,否則默認False。
processlinks:是一個callable或string(該Spider中同名的函數(shù)將會被調用)。從linkextrator中獲取到鏈接列表時將會調用該函數(shù)。該方法主要是用來過濾。
processrequest:是一個callable或string(該spider中同名的函數(shù)都將會被調用)。該規(guī)則提取到的每個request時都會調用該函數(shù)。該函數(shù)必須返回一個request或者None。用來過濾request。
參考鏈接:https://scrapy-chs.readthedocs.io/zhCN/latest/topics/spiders.html#topics-spiders-ref
通用爬蟲案例
CrawlSpider整體的爬取流程:
爬蟲文件首先根據(jù)url,獲取該url的網(wǎng)頁內容
鏈接提取器會根據(jù)提取規(guī)則,對步驟1網(wǎng)頁內容中的鏈接進行提取
規(guī)則解析器會根據(jù)指定的解析規(guī)則,將鏈接提取器中提取到的鏈接按照指定的規(guī)則進行解析
將3中解析的數(shù)據(jù)封裝到item中,最后提交給管道進行持久化存儲
創(chuàng)建CrawlSpider爬蟲項目
創(chuàng)建scrapy工程:scrapy startproject projectName
創(chuàng)建爬蟲文件(切換到創(chuàng)建的項目下執(zhí)行):scrapy genspider -t crawl spiderName www.xxx.com
--此指令對比以前的指令多了 "-t crawl",表示創(chuàng)建的爬蟲文件是基于CrawlSpider這個類的,而不再是Spider這個基類。
啟動爬蟲文件(基于步驟二的路徑執(zhí)行):scrapy crawl crawlDemo
案例(爬取小說案例)
測試小說是否可用
本案例是17k小說網(wǎng)小說爬取,打開首頁---->選擇:分類---->選擇:已完本、只看免費,如下圖:
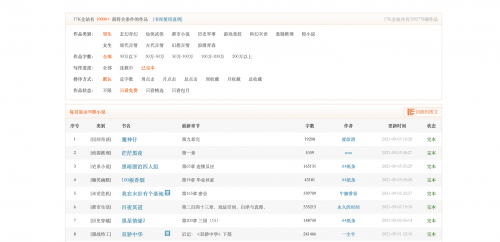
鏈接:https://www.17k.com/all/book/200030101.html
按照上面的步驟我們依次:
scrapy startproject seventeen_k
scrapy genspider -t crawl novel www.17k.com
Pycharm 打開項目
查看novel.py
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(allow = LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',follow=True, process_links="process_booklink"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("限制一本書:", link.url)
yield link
else:
return
def parse_book(self, response):
item = {
return item
首先測試一下是否可以爬取到內容,注意rules給出的規(guī)則:
Rule(allow = LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrictxpaths=('//td[@class="td3"]')),
callback='parsebook',follow=True, processlinks="processbooklink")
在allow中指定了提取鏈接的正則表達式,相當于findall(r'正則內容',response.text),在LinkExtractor中添加了參數(shù)restrict_xpaths是為了與正則表達式搭配使用,更快的定位鏈接。
callback='parse_item'是指定回調函數(shù)
process_links用于處理LinkExtractor匹配到的鏈接的回調函數(shù)
然后,配置settings.py里的必要配置后運行,即可發(fā)現(xiàn)指定頁面第一本小說URL獲取正常:
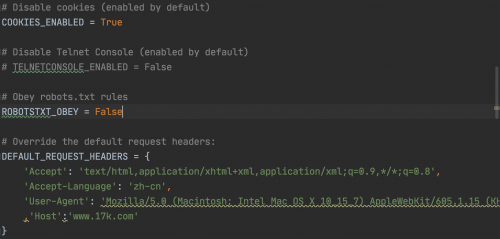
執(zhí)行:scrapy crawl novel ,運行結果:
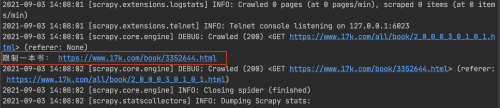
解析小說的詳細信息
上圖鏈接對應小說的詳情頁: https://www.17k.com/book/3352644.html
通過解析書籍的URL的獲取到的響應,獲取以下數(shù)據(jù):
catagory(分類),bookname,status,booknums,description,ctime,bookurl,chapter_url
改寫parse_book函數(shù)內容如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')), callback='parse_book',
follow=True, process_links="process_booklink"),
)
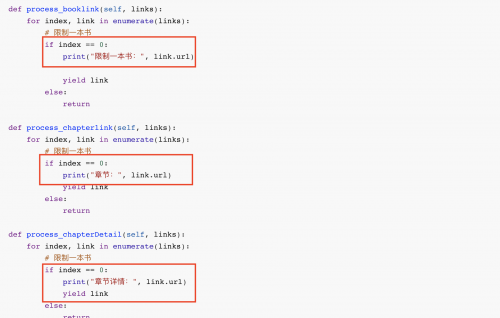
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("限制一本書:", link.url)
yield link
else:
return
def parse_book(self, response):
item ={}
print("解析book_url")
# 字數(shù):
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 書名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分類
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# 小說鏈接
book_url = response.url
# 小說章節(jié)
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
print(book_nums, book_url,book_name,category,description,chapter_url)
return item
打印結果:
解析章節(jié)信息
通過解析書籍的URL獲取的響應里解析得到每個小說章節(jié)列表頁的URL,并發(fā)送請求獲得響應,得到對應小說的章節(jié)列表頁,獲取以下數(shù)據(jù):id , title(章節(jié)名稱) content(內容),ordernum(序號),ctime,chapterurl(章節(jié)url),catalog_url(目錄url)
在novel.py的rules中添加:
...
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章節(jié)目錄的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
)
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("章節(jié):", link.url)
yield link
else:
return
...
通過上圖可以發(fā)現(xiàn)從上一個鏈接的response中,匹配第二個rule可以提取到章節(jié)的鏈接,繼續(xù)編寫解析章節(jié)詳情的回調函數(shù)parse_chapter,代碼如下:
# 前面代碼省略
......
def parse_chapter(self, response):
print("解析章節(jié)目錄", response.url) # response.url就是數(shù)據(jù)的來源的url
# 注意:章節(jié)和章節(jié)的url要一一對應
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
print('章節(jié)目錄:', chapter_list)
重新運行測試,發(fā)現(xiàn)數(shù)據(jù)獲取正常!
獲取章節(jié)詳情
通過解析對應小說的章節(jié)列表頁獲取到每一章節(jié)的URL,發(fā)送請求獲得響應,得到對應章節(jié)的章節(jié)內容,同樣添加章節(jié)的rule和回調函數(shù).完整代碼如下:
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章節(jié)目錄的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
# 解析章節(jié)詳情
Rule(LinkExtractor(allow=r'/chapter/(\d+)/(\d+).html',
restrict_xpaths=('//dl[@class="Volume"]/dd')), callback='get_content',
follow=False, process_links="process_chapterDetail"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("限制一本書:", link.url)
yield link
else:
return
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("章節(jié):", link.url)
yield link
else:
return
def process_chapterDetail(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("章節(jié)詳情:", link.url)
yield link
else:
return
def parse_book(self, response):
print("解析book_url")
# 字數(shù):
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 書名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分類
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# 小說鏈接
book_url = response.url
# 小說章節(jié)
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
print(book_nums, book_url, book_name, category, description, chapter_url)
def parse_chapter(self, response):
print("解析章節(jié)目錄", response.url) # response.url就是數(shù)據(jù)的來源的url
# 注意:章節(jié)和章節(jié)的url要一一對應
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
print('章節(jié)目錄:', chapter_list)
def get_content(self, response):
content = "".join(response.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()').extract())
print(content)
同樣發(fā)現(xiàn)數(shù)據(jù)是正常的,如下圖:
進行數(shù)據(jù)的持久化,寫入Mysql數(shù)據(jù)庫
a. 定義結構化字段(items.py文件的編寫):
class Seventeen_kItem(scrapy.Item):
'''匹配每個書籍URL并解析獲取一些信息創(chuàng)建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field()
book_name = scrapy.Field()
book_nums = scrapy.Field()
description = scrapy.Field()
book_url = scrapy.Field()
chapter_url = scrapy.Field()
class ChapterItem(scrapy.Item):
'''從每個小說章節(jié)列表頁解析當前小說章節(jié)列表一些信息所創(chuàng)建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
chapter_list = scrapy.Field()
class ContentItem(scrapy.Item):
'''從小說具體章節(jié)里解析當前小說的當前章節(jié)的具體內容所創(chuàng)建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
chapter_detail_url = scrapy.Field()
b. 編寫novel.py
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sevencat.items import Seventeen_kItem, ChapterItem, ContentItem
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章節(jié)目錄的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
# 解析章節(jié)詳情
Rule(LinkExtractor(allow=r'/chapter/(\d+)/(\d+).html',
restrict_xpaths=('//dl[@class="Volume"]/dd')), callback='get_content',
follow=False, process_links="process_chapterDetail"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("限制一本書:", link.url)
yield link
else:
return
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("章節(jié):", link.url)
yield link
else:
return
def process_chapterDetail(self, links):
for index, link in enumerate(links):
# 限制一本書
if index == 0:
print("章節(jié)詳情:", link.url)
yield link
else:
return
def parse_book(self, response):
print("解析book_url")
# 字數(shù):
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 書名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分類
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# # 小說鏈接
book_url = response.url
# 小說章節(jié)
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
# print(book_nums, book_url, book_name, category, description, chapter_url)
item = Seventeen_kItem()
item['book_nums'] = book_nums
item['book_name'] = book_name
item['category'] = category
item['description'] = description
item['book_url'] = book_url
item['chapter_url'] = chapter_url
yield item
def parse_chapter(self, response):
print("解析章節(jié)目錄", response.url) # response.url就是數(shù)據(jù)的來源的url
# 注意:章節(jié)和章節(jié)的url要一一對應
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
# print('章節(jié)目錄:', chapter_list)
item = ChapterItem()
item["chapter_list"] = chapter_list
yield item
def get_content(self, response):
content = "".join(response.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()').extract())
chapter_detail_url = response.url
# print(content)
item = ContentItem()
item["content"] = content
item["chapter_detail_url"] = chapter_detail_url
yield item
c. 編寫管道文件:
import pymysql
import logging
from .items import Seventeen_kItem, ChapterItem, ContentItem
logger = logging.getLogger(__name__) # 生成以當前文件名命名的logger對象。 用日志記錄報錯。
class Seventeen_kPipeline(object):
def open_spider(self, spider):
# 連接數(shù)據(jù)庫
data_config = spider.settings["DATABASE_CONFIG"]
if data_config["type"] == "mysql":
self.conn = pymysql.connect(**data_config["config"])
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 寫入數(shù)據(jù)庫
if isinstance(item, Seventeen_kItem):
# 寫入書籍信息
sql = "select id from novel where book_name=%s and author=%s"
self.cursor.execute(sql, (item["book_name"], ["author"]))
if not self.cursor.fetchone(): # .fetchone()獲取上一個查詢結果集。在python中如果沒有則為None
try:
# 如果沒有獲得一個id,小說不存在才進行寫入操作
sql = "insert into novel(category,book_name,book_nums,description,book_url,chapter_url)" \
"values(%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (
item["category"],
item["book_name"],
item["book_nums"],
item["description"],
item["book_url"],
item["catalog_url"],
))
self.conn.commit()
except Exception as e: # 捕獲異常并日志顯示
self.conn.rollback()
logger.warning("小說信息錯誤!url=%s %s") % (item["book_url"], e)
return item
elif isinstance(item, ChapterItem):
# 寫入章節(jié)信息
try:
sql = "insert into chapter (title,ordernum,c_time,chapter_url,chapter_url_refer)" \
"values(%s,%s,%s,%s,%s)"
# 注意:此處item的形式是! item["chapter_list"]====[(title,ordernum,c_time,chapter_url,chapter_url_refer)]
chapter_list = item["chapter_list"]
self.cursor.executemany(sql,
chapter_list) # .executemany()的作用:一次操作,寫入多個元組的數(shù)據(jù)。形如:.executemany(sql,[(),()])
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章節(jié)信息錯誤!%s" % e)
return item
elif isinstance(item, ContentItem):
try:
sql = "update chapter set content=%s where chapter_url=%s"
content = item["content"]
chapter_detail_url = item["chapter_detail_url"]
self.cursor.execute(sql, (content, chapter_detail_url))
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章節(jié)內容錯誤!url=%s %s") % (item["chapter_url"], e)
return item
def close_spider(self, spider):
# 關閉數(shù)據(jù)庫
self.cursor.close()
self.conn.close()
其中涉及到settings.py的配置:
DATABASE_CONFIG={
"type":"mysql",
"config":{
"host":"localhost",
"port":3306,
"user":"root",
"password":"root",
"db":"noveldb",
"charset":"utf8"
}
}
數(shù)據(jù)庫的表分別為:
novel表字段有:
id(自動增長的)
category
book_name
book_nums
description
book_url
chapter_url
chapter表字段有:
id
title
ordernum
c_time
chapter_url
chapter_url_refer
conent
如果想獲取多頁的小說則需要加入對start_urls處理的函數(shù),通過翻頁觀察每頁URL的規(guī)律,在此函數(shù)中拼接得到多頁 的URL,并將請求發(fā)送給引擎!
......
page_num = 1
#start_urls的回調函數(shù)
# 作用:拼接得到每頁小說的url。實現(xiàn)多頁小說獲取。
def parse_start_url(self, response):
print(self.page_num,response)
#可以解析star_urls的response 相當于之前的parse函數(shù)來用
#拼接下一頁的url
self.page_num+=1
next_pageurl='https://www.17k.com/all/book/2_0_0_0_3_0_1_0_{}.html'.format(self.page_num)
if self.page_num==3:
return
yield scrapy.Request(next_pageurl)
注意:在每個對應的processxxxx的回調函數(shù)中都是獲取index=0的小說,文章等,可以修改比如processchapterlink中的index<=20,那就是更多的章節(jié)信息了。
ok抓緊時間測試一下吧!相信你會收獲很多!














 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號